群聊周报 Vol.1|我花两天用 AI 整理了一年账单,然后开始算 AI 的账
※ 本周报素材来自鸭哥创建的 AI 从业者微信群。群友均以匿名昵称出现。完整每日日报在 GitHub 上每日发布:https://louyu2015.github.io/AI-chatgroup-daily/
文章由作者和 Claude Opus 联合撰写。题图由 GPT-Images 2 生成。
我用 AI 整理了一年银行账单,爽完之后开始肉疼
前阵子我干了件特别”AI 原住民”的事——让 AI 帮我把一整年、好几个账户的银行流水全下载下来,清洗、归类,与我的记账软件记录的数据对比。
以前我是怎么做的呢?我需要一个文件一个文件地下载,一行一行地比对。现在我只要登录自己的银行账号,一句话扔过去,电脑就自己翻网页、吐出一段分析,就像有一个隐形人在操作电脑一样。爽是真的爽,可代价也来了:token 烧得太快,我大概一个多小时就用光了 Claude Code 的 5 小时限额。我只好轮流薅 Gemini CLI、Codex 和 Claude Code 的限额,硬是折腾了两天才跑完。我不是一个人,在 AI 群里,有大量重度用户在苦苦等着限额重置。@豁达的灰熊 有一句精准吐槽:
每天跟做手游每日任务一样把额度用完。
后来我又算了另外一笔账。我自己有个机器人每天用 Claude API 总结群聊日报,一天差不多花费 1 美元,一个月就是 30 美元。作为一个心甘情愿掏钱的 AI 爱好者,我咬咬牙也就认了。可如果是一个普通人,会仅仅为了”帮我读读群聊”这么个小工具,每月心甘情愿地掏 30 美元吗?
这恰恰是这周群里吵得最热的那条暗线:我们现在享受的 AI 价格,根本不是真实的。
微软嫌贵砍了 Claude Code
最近,一个新闻在群里被热议。微软取消了内部的 Claude Code 订阅,原因是成本不可控。要知道,这可是一家 3 万亿美元市值、净利润上千亿的公司。
@勇敢的鸵鸟 当即扔了个问题:
Cancel Claude Code 怎么能减少 token usage?Copilot 不是一样用 tokens。
一句话把真正的痛点拎了出来。贵的不是”用 Claude”还是”用 Copilot”,贵的是”按 token 计费”这个模式第一次把被订阅制隐藏的成本明晃晃亮给了所有人看。
坏消息接踵而至。Uber CTO 发内部备忘录说公司四个月就烧光了全年 AI 预算,一个工程师每月 Claude Code 花掉 500 到 2000 美元;GitHub Copilot 从固定费率切成按量计费,小红书上立刻有人晒出爆掉的账单。@稳重的海豚 说额度”转眼就没了”,已经在把工作流从 Claude 迁往 Codex。@低调的北极熊 体感更猛:
用量真的是指数增长的……基建完备的情况下可以 24h 不停。
200 美元的月卡,真实成本 8000 美元
@沉稳的仓鼠 发了一张用 AI 做的信息图:根据 SemiAnalysis 测算,200 美元一个月的 coding 套餐,按 API 实际消耗折算下来大概值 5000 到 8000 美元!当然 API 零售价不等于真实成本。Anthropic 推理毛利率约 70%,实际算力成本约为其三分之一,但依然是亏损的。这不叫良心定价,这叫补贴。
更直接的证据是 OpenAI 自己承认的。早在 2025 年初,Sam Altman 就公开说,昂贵的 200 美元 ChatGPT Pro 套餐竟是赔本买卖——”人们用得比我们预期多太多”。

那么问题来了:谁在替我们这些用户买这个单?
“外卖大战”烧到了美国
答案是 VC 投资。这剧情我们刚看过一遍——中国的外卖大战。
2025 年,美团、阿里、京东为了抢即时零售,半年里直接烧掉了 800 到 1000 亿人民币的补贴。结果是什么?美团从 2024 年盈利 358 亿,直接转成 2025 年预亏最高 243 亿。三毛钱一杯的咖啡,是真金白银堆出来的,目的只有一个:烧死对手、锁住用户。
AI 这边,剧本一模一样,只是数字更夸张。OpenAI 2024 年亏约 50 亿美元,2026 年一年预计要亏 140 亿。a16z 干脆把 AI 订阅类比成 Uber 早期定价。你以为是市场价,其实是投资人在替你花钱。
群里 @直率的鹦鹉 无意间还原了”外卖红包”的现场:他说这个月综合成本最低的居然是 ChatGPT Pro,因为”各种重置各种 2x 额度”。你品品:额度重置、加倍赠送,不就是打车红包和外卖满减换了个皮吗?
补贴要还了,但不是简单地”涨价”
外卖大战的结局我们都知道:补贴退潮、价格回归、监管出手。AI 的补贴,也快还了。
退潮就发生在现在。2025 年 8 月,Anthropic 头一回给 Claude 订阅加了每周限额,超出部分要按 API 原价另买。同年,Cursor 把固定额度悄悄换成积分池,很多用户超额爆了账单,逼得官方公开道歉退款。最狠的一刀发生在今年 4 月:Anthropic 禁止 OpenClaw 这类第三方工具借订阅的壳调用 Claude,同时逐渐收紧各种绕过方式,这种补贴它再也烧不起了。一年之内,几乎所有主流工具都在做同一件事:计量、限额、加钱。
催债的是 IPO。SpaceX、OpenAI、Anthropic 三家几乎同期递交上市文件,总估值超过 3.5 万亿美元。一旦上市,财报压力就来了。你不能一边喊着给股东谋福利,一边继续给用户发”满减券”。
不过不是”AI 公司”集体勒裤腰带——两家虽然都还在净亏,但亏损的性质完全不同。Anthropic 本季度预计将交出首份转正的季度经营利润(注意只是经营利润,不包括训练和股权激励等成本),推理毛利率约 70%,基本盘是 toB。它的亏损主要亏在前瞻性的训练投入上。而 OpenAI 今年即将净亏约 140 亿,上季度的经营利润率约为 -122%,预计 2029–2030 年才能转正,亏损大头在 toC 业务——9 亿用户里只有约 5.5% 在付费。@80-HD 看得透:
2C 就是比 2B 难赚钱。
所以补贴这事,对 OpenAI 是战略刚需,它需要消费端的规模叙事来撑住近万亿估值的 IPO;Anthropic 的企业端已经快盈利了,还在主动收紧消费端额度,反倒不必硬撑。
天花板在升,地板在塌
那以后 AI 到底是变贵还是变便宜?我的看法是:涨价和降价都在发生,只是它们说的不是同一个东西。
先说顶尖模型的天花板——它会一直往上升。想让模型变得更聪明会越来越难。据 Epoch AI 统计,前沿模型的训练成本这些年差不多每年涨 2.4 倍。最典型的是 Anthropic 还没正式发布的 Mythos——泄漏的内部文件显示该模型规模达到了 10 万亿参数,官方后续公布的描述也说”对我们服务成本极高,对客户使用成本也极高”,目前只放给少数企业和政府做预览。最强的那个模型,注定一直贵,因为”更聪明”本身就没有止境。
再说地板,它在飞快地塌。”够用”的模型正在以肉眼可见的速度变白菜价:
DeepSeek 把训练成本压到极致——V3 的训练只花了约 600 万美元、280 万 GPU 小时,而同级别的 Llama 3 405B 要 3080 万 GPU 小时,效率差一个数量级。DeepSeek 用的 FP8、MLA、MoE、MTP 这些招数,全是开源、人人可用的。
硬件也在降本。英伟达 Blackwell 比上一代每百万 token 成本降 15 倍;新一代 GB300 对推理任务做到每兆瓦吞吐 50 倍、单 token 成本 1/35。
算下来,经济档模型的价格”半衰期”只有 1.1 年,比摩尔定律的 2 年还快。token 价格两年降了近 280 倍。
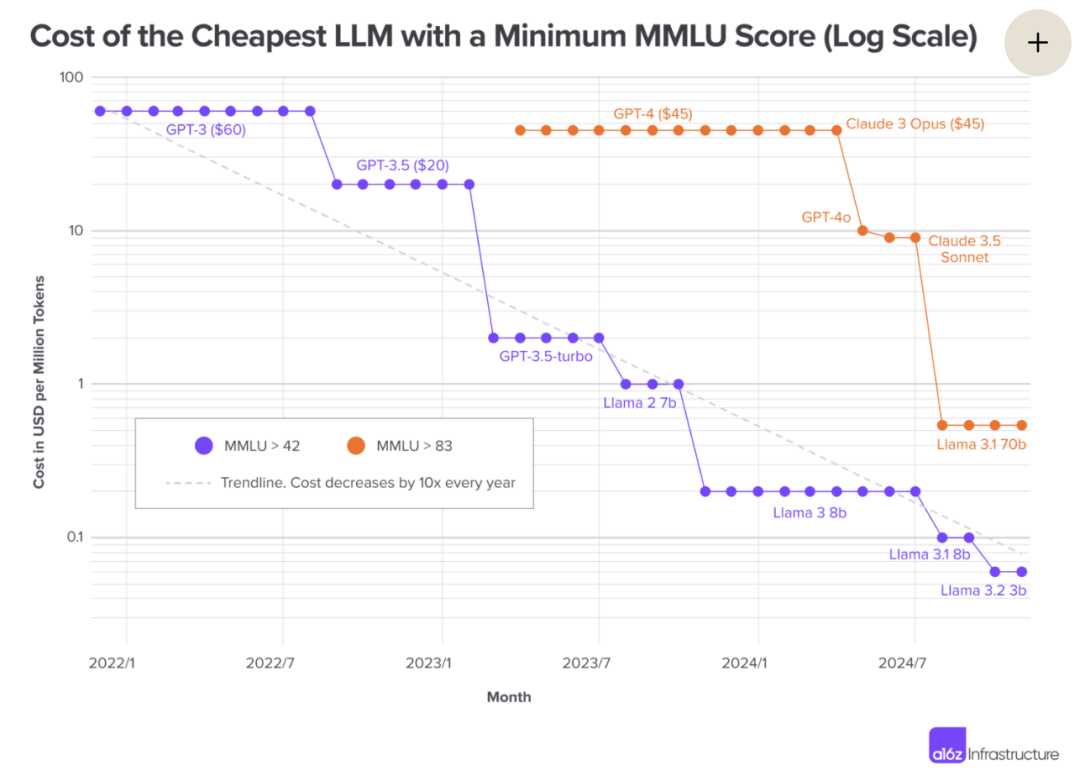
这里要较个真:严格说这已经不是”摩尔定律”了。经典摩尔定律(靠制程缩小)其实正在失速。Blackwell 几乎没有真正的制程进步,性能翻倍靠的是架构和系统级协同设计。所以推动地板下塌的,不是晶体管,是整套系统的协同优化。
天花板上升、地板塌陷,中间的剪刀差越拉越大。所以”涨价派”和”降价派”其实都没错——他们只是一个在仰头看天花板,一个在低头看地板。
如果说过去两年用 AI 的关键词是”能不能实现自动化”,那接下来的关键词,是“这事到底配不配得上最贵的模型”。
补贴退潮 + 成本下降,合起来其实是个好消息。你不必为所有任务都付最高价。整理银行流水、跑个格式转换、总结群聊这些活,一个便宜十倍的”够用”模型完全扛得住,没必要动用 Opus 这种高级脑子。你可以把贵模型留给真正难、真正需要判断力的环节,然后用便宜的模型处理量大的工作。
值得注意的是,单价跌了不代表你账单会变少,因为成本下降以后,你就会让它干更多活。真正省钱的,不是少用 AI,而是给每个任务派一个配得上它的模型。
野蛮生长的时代培养了我们”不看价格用 AI”的习惯。这个习惯需要改一改了。
办公室变成了”高端呼叫中心”
硅谷创业公司的办公室最近有了个新外号:高端呼叫中心。@低调的仓鼠 转发了 TechCrunch 的观察:一位 VC 说他走进办公室,没人打字,也没人开会,却有一屋子工程师压着嗓子对着电脑嘟嘟囔囔。原来他们正在用语音输入法指挥 AI 干活。
我也在干同样的事,只不过我的段位还很低。我只是拿 iPhone 自带语音输入法写提示词,避免手酸。但中英文一混、术语一多,iPhone 的识别就乱套了,一些错别字甚至会把 AI 误导到沟里去。而且说实话,我只会在家里这么做,真要在公司对着电脑念叨,感觉有点奇怪。识别不靠谱,加上不好意思开口。语音输入想从极客玩具变成主流工具,最要命的就是这两道坎。
语音输入赛道的势头倒是够猛的。OpenAI Codex 和 Claude Code 这周都加了原生语音模式;Wispr Flow 估值已经到 20 亿美元。说话本来就比打字快三到五倍,效率账是实打实的。可一旦当真用起来,坑一个接一个。
@细心的猫头鹰发现 Whisper 大模型遇到安静的片段就开始无限复读”感谢观看”,原因是训练数据里塞满了 YouTube 视频,片尾没有声音却有”感谢观看”的字幕。
Typeless 这类 app 体验本来不错,却被 iOS 的后台策略限制逼得只能一直挂在后台偷偷录音,非常费电。
你以为买个好麦就能提高输入准确率?群里实测 Insta360、DJI 这些热门麦克风,蓝牙连接时走的都是”打电话链路”最高 16kbps 的全损音质。它们是为录 vlog 设计的,没有一个是为”对着电脑编程”设计的。
语音输入卡住不是因为”听不懂”。随着 AI 的发展,语音识别这事正在变得又好又便宜。真正难搞的全在它周围——系统集成、麦克风适配、隐私顾虑,以及你那没有隔间的开放办公室。
如果你想试试语音编程,这些是群友的建议:
需要省事:选 Wispr Flow 或 Typeless,识别准但需要联网。
需要隐私:选 superwhisper 或 Aqua Voice,你的架构决策和密钥不用念给云端的服务器听。
国内:选豆包输入法(@豁达的灰熊 力荐离线模式)或 CapsWriter-Offline,完全离线开源。
群里 @今天群内信息量极大 自己 vibe code 的 VoiceFlow 也值得一试,@冷静的飞鼠 的评价是”远远吊打市面其他所有 app”:https://github.com/grapeot/voiceflow
所以机会不在更聪明的耳朵:在手机上把集成做顺、在转写里塞进”懂你术语”的能力、在不上云的前提下做出云端级的体验——每一个都是大生意。但最硬、也最反直觉的那块,压根不是技术问题:怎么让你敢在同事面前开口。
一年前放弃的东西,我一天就写出来了
去年我想给自己用的记账软件 MoneyDance 写个插件,分析我的投资收益率。然而我翻了半天 Java API 文档以后放弃了。想理解一个全新的大型项目,真的太费精力了。
上个月,我拿 Claude Code 重新试了一下。出乎意料的是,这次我只是描述了一下我的需求,一天就搞定了。现在我的 Claude Code 可以通过插件查询整个 MoneyDance 数据库,整理消费分类、做现金流分析,预测定投一年后各类资产的比例。我马上成为了 Claude Code 的死忠粉。
AI 对我最大的改变不是”写得快”,是”敢动手”。以前我看到复杂 API 就绕道走,现在我可以让 AI 去啃文档。
但这一天里它也卡过:它要读一个 Java API 的字段,光看文档猜方法名,猜错了,读出来全是 0,于是在原地打转。有意思的是它怎么解套的。它最终自己提了个办法:写一个探测命令,把那个 Java 对象的真实结构打印出来看看。这一步是 AI 自己想到的,不是我。
但它给的是个半成品:我要自己把命令复制到 MoneyDance 的调试控制台里,再把结果复制回来喂给它,然后再进行下一个测试,一来一回好几轮。于是我提醒它,”你写一个新的临时插件,把各种方案一次性一起试一下,把需要的信息全取出来”。这一下就省掉了那串手动复制粘贴的来回,只要我在控制台里启动一次插件,它立刻解套,一次改对。
所以那一下值钱的,不是”我比它聪明”——探测的点子是它先想到的。值钱的是:我看出它那个半成品会把人拖进反复的手动操作,知道该把它逼成一个能自己闭环、不用伺候的模式。
粉笔记号往上挪了一层
说到这儿我想起一个老故事,虽然可能是杜撰的。工厂发电机坏了,一帮工程师搞不定,请来电气专家 Steinmetz。他听了两天,爬上去用粉笔画了道记号:拆这儿,换 16 圈线圈。修好了以后,他开出账单:一万美元。厂方嫌贵,要他给出账单明细。他写道:“画粉笔记号 1 美元。知道往哪儿画 9999 美元。”
以前这故事的寓意是:答案本身不值钱,知道答案才值钱。可到了 AI 时代要拧一下——现在 AI 也能找到答案了。那 9999 美元到底买的是什么?是知道怎么帮助它找到答案。粉笔记号没消失,只是往上挪了一层:从”知道答案”挪到了”知道怎么让机器吐出答案”。
AI 的毛病是真的:会幻觉、会过度设计、会生成一堆能跑但没人敢维护的垃圾代码,会像我那次一样对着文档原地打转。但人的价值,早就不在“把代码敲出来”了——在知道该把软件摆在哪个位置、什么时候该逼 AI 换条路。
壁垒不在”能用”,在”敢用”
不过”会驾驭”还只是个人手艺,真正的壁垒在更后面。
我自己用,跑通就行。可企业客户要的从来不是”能用”——是稳定、是安全、是出了事有人负责。demo 越来越多,真正敢托付的产品却依然很稀缺。把一个模型塞进真实业务、让它稳定可信地跑起来,这件事 AI 自己解决不了。
这句话有个活生生的注脚,是最近群里和业界都在热议的一个职业:FDE,前线部署工程师。这角色一点都不新。Palantir 和微软等公司多年前就有。工程师直接驻扎到客户现场,把 SharePoint 等产品部署到客户那里,并与客户沟通,把产品融入客户的工作流。只是最近这一职业的热度突然窜了起来,招聘岗位一年暴涨 800%,通常起薪 30 万美元,资深工程师可达 60 万+美元。OpenAI 和 Anthropic 也先后下场做这块业务。群里 @80-HD 就提到,他们公司有个 OpenAI 的 FDE 在推进 Codex 集成。
它存在的理由一句话就能概括:企业 AI 试点 95% 失败,不是因为模型能力不行,是因为部署方案没搞定。模型越强,”把它真正用起来”就越值钱。这就是”采用在升值”。
我们正在锯掉程序员的梯子
那程序员会消失吗?群友的判断是:不是消失,是价值整体往上挪了。只会”生成”那半(写代码)的人在被挤压,能往”判断 + 采用”那半走的人在升值。
数据是冷的:根据哈佛对 28 万家企业的追踪研究,一个企业采用生成式 AI 以后,初级开发就业会在六个季度内减少 9–10%,而高级岗位几乎不动;Handshake 2025 数据显示入门级软件工程岗位同比下降约 30%;Indeed Hiring Lab 的数据显示,Web、Android、iOS、后端等传统开发岗位的招聘发布数量从 2020 年 2 月到 2025 年年中跌了 60% 以上。当然,这不全怪 AI。CS 毕业生数量十年间翻了倍,疫情后的过度招聘也在回调。
但真正让人后背发凉的是另一层。@开朗的企鹅 转述了 Martin Fowler 的观点:如果 vibe coding 切断了学习循环,就没人能成长为高级工程师。把两件事并起来看——今天被抢疯、被炒上天的高级工程师,正是通过那些被 AI 干掉的初级杂活培养出来的。现在我们锯掉了职业阶梯里最低那几级。短期来说,高级工程师会更稀缺、更贵。可是长期来看,新的高级工程师从哪儿来?
写完这三个话题回头一看,它们讲的其实是同一件事。
Token 越来越便宜;语音识别越来越便宜;写代码越来越便宜;凡是 AI 能直接“生成”的东西,都在加速贬值。而知道该在哪儿“划线”的判断力在升值;让模型被信任、被采用的部署能力在升值;把虚拟世界和真实世界缝合起来的集成能力在升值。